偶然看到这样一篇关于码农的小说, 感觉还可以, 就想收集下来慢慢看.
但是都是网页而且还挺多, 就看看有没有整理好的全本, 搜了一下没找到.
接着就手动复制粘贴, 贴了几篇感觉太枯燥, 就琢磨着如何使用 requests 和 BeautifulSoup 来提取文本.
很少使用 BeautifulSoup, 所以临时去看了一下文档, 开始走起.
先用浏览器的
审查元素获取分页的页面结构, 这里我们只需要标题和链接地址即可分析页面内容抓取
标题和链接地址, 还一并抓取当前的章节, 否则就没法知道顺序了根据获取的链接抓取全文
分析全文, 在
entry下面的p和span里, 一开始我以为都在p结构里, 结果最后发现有的章节是空的, 看了下空的章节的结构, 原来用的是<div><span>...</span></div>的结构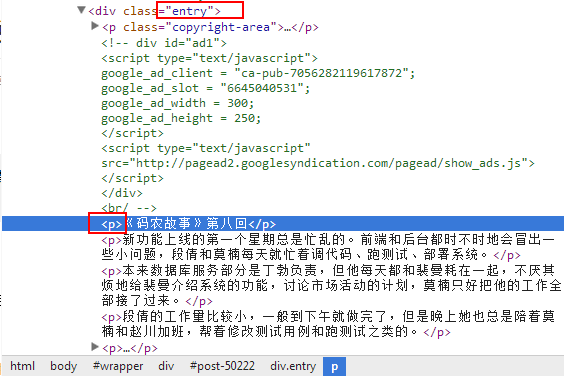

这些都确定了后就可以开工了, 当然我是逐步确定的. 我的流程是: 按章节写到单独的文件里, 最后再合并. 好了,
Talk is cheap, show me the code.:coder_story.py 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63#!/usr/bin/env python
#-*- coding: utf-8 -*-
import os
import os.path
import requests
from bs4 import BeautifulSoup
import re
digit_re = re.compile('(\d+-?\d*)')
url = r'http://blog.jobbole.com/tag/%E7%A0%81%E5%86%9C%E6%95%85%E4%BA%8B/page/{}/'
if not os.path.exists('coder_story'):
os.makedirs('coder_story')
os.chdir('coder_story')
for page in (1, 2, 3):
r = requests.get(url.format(page))
# soup = BeautifulSoup(r.content) # lxml未安装时用这行
soup = BeautifulSoup(r.content, 'lxml')
for meta_title in soup.find_all('a', class_='meta-title'):
# 我们要的都必须有title
if 'title' not in meta_title.attrs:
continue
# 不是这个小说不要
if u'老码农原创小说' not in meta_title['title']:
continue
print(meta_title) # 打印一下标题
href = meta_title.get('href') # 获取文章链接
# 获取章节序号
found = digit_re.findall(meta_title['title'])
if not found:
continue
# 个位数章节前补0, 为了后面的合并
page_no = found[0]
if int(page_no.split('-')[0]) < 10:
page_no = '0' + page_no
# 获取文章的内容
r2 = requests.get(href)
# s2 = BeautifulSoup(r2.content) # lxml未安装时用这行
s2 = BeautifulSoup(r2.content, 'lxml')
entry = s2.find('div', class_='entry')
with open('{}.txt'.format(page_no), 'w') as f:
# 内容在 <p>...</p> 或 <div><span>...</span></div>里
for p in entry.find_all(['p', 'span']):
# copyright-meta部分, 跳过
if p.get('class'):
continue
# 空白行, 文件里写两行空白, 便于阅读
text = p.get_text()
if not text:
f.write('\r\n\r\n')
continue
f.write(text.encode('utf-8') + '\r\n')
# "待续" 的地方, 接着就是另一章了, 插入空行
if text.endswith(u'<\u5f85\u7eed>'):
f.write('\r\n')合并到一个文件, 用
Python碰到编码错误, 时间紧, 就用批处理好了, 还简单1
copy *.txt 码农故事.txt
打完收工.
后记:
就在合并时, 看到最后的一句话, 马上吐出一升老血:


不过, 在 kindle 上还是 txt 的效果好一些, pdf 转换的有些乱码, 不完美.

附下载地址:
原文链接: http://lixxu.github.io/2014/07/25/get-coder-story-text-from-web/
版权声明: 转载请注明出处.